
Выскажусь по теме, которая некоторое время назад была хайповой, пока она, вроде бы, совсем не протухла.
DISCLAIMER: в этой области сейчас всё очень быстро меняется, поэтому высока вероятность, что этот текст устареет сразу после публикации (если не до).
Для читателей, совсем далёких от мира информационных технологий, коротко поясню: вайбкодинг — это когда программирует не программист, а нейросеть.
Идея в том, чтобы взять какой-нибудь Codex / Claude Code / Qwen Code / Cline / Roo / Augment / Gemini CLI / Cursor / Windsurf / Trae / Aider (их очень много сейчас всяких-разных) и сказать ему что-то вроде «дорогая ГПТ-шка, напиши мне второй фейсбук, который сделает меня богатым, но только без багов», а та как возьмёт, да как напишет…
Напишет что-то.
И я даже затрудняюсь определиться, какое из этих слов выделить: да, это будет «что-то» (скорее всего, не то, не так и не тогда), с другой стороны, оно всё-таки будет.

Set and setting
Для тех, кто пришёл сюда из поисковика, скажу, что я не IT-специалист, я психолог, поэтому включайте скептицизм на максимум.
Ну, и минутка рекламы, как же без этого: покупайте наших слонов (ну, то есть психологические сессии).
Тестировал я всё нижеперечисленное на нескольких небольших проектах (в основном в духе «тут дёрнем одну API-шку, там — другую»), самый крупный из которых на момент написания имеет порядка 30 тысяч строк кода.
Как оно на кодовых базах с миллионами строк — без понятия, поскольку не имел удовольствия попробовать.
Язык — Python, из которого я упорно пытаюсь сделать что-то статически типизированное, навешивая все линтеры / тайп-чекеры, до которых могу дотянуться (вот такое извращение, почему не взять сразу что-то статически типизированное — я не отвечу, ибо «так сложилось исторически» ©).
Кто / что?
Я пробовал разные инструменты и по итогу в качестве основной рабочей лошадки выбрал Claude Code.
Почему?
Во-первых, тарифная политика: за 100 USD ты получаешь не самого плохого агента в режиме «сколько-то сообщений каждые 5 часов».
На практике это означает, что где-то часа полтора — два можно активно вайбкодить, потом нужно ждать ещё часа три.
Во-вторых, Claude Code действительно неплохо умеет дёргать разного рода внешние инструменты: MCP-серверы (см. ниже), утилиты командной строки, кастомные скрипты и прочее подобное.
В-третьих, как бы ни ругали в августе — сентябре Sonnet 4 (это основная рабочая LLM в Claude Code), на мой взгляд, она всё ещё неплоха.
Поскольку основной практический опыт у меня именно с Claude Code (Sonnet 4), писать буду про него.
При этом могу сказать, что концептуально остальные не сильно отличаются, а вот в конкретных деталях другие агенты могут быть радикально иными. Но я постараюсь объяснять сами принципы и закономерности, не сильно привязываясь к деталям реализации.
Чем я ещё пользуюсь?
Google Gemini CLI — для множественных быстрых, но не слишком заковыристых правок.
Нужно поправить кучу тестов после рефакторинга? Это сюда. Требуется поменять интерфейсы, но лениво юзать sed? Вполне подойдёт.
Осознал, что надо бы поменять зависимость в криво спроектированном коде? Норм задача.
В интернетах часто говорят, что Gemini невообразимо прекрасен на сложных задачах. В режиме LLM для Zen MCP (см. далее) версия 2.5-pro мне и правда очень зашла.
А вот в режиме гугловского агента (собственно, Gemini CLI) — не особенно: не слушается, инструментами пользуется криво, контекст хоть и большой, но расплывается.
OpenAI Codex — для планирования и сложных задач (наряду с режимом планирования и моделью Opus 4.1 в Claude Code).
Умная, часто видит косяки, которых не замечает Sonnet 4 (дефолтная LLM в Claude Code), но хуже UX/UI, а также использование инструментов (ниже постараюсь объяснить, чего я к этим инструментам так прицепился).
How much is the fish?
На момент написания статьи вся это радость съедает ежемесячно:
1. Claude Code (Max 5x) — 100 USD.
2. ChatGPT Plus — 20 USD.
3. Google Workspace на двух пользователей — 28 USD.
Итого — 148 USD (или 12 400 RUR, или 400 GEL — по курсу на момент написания).
Жируют психолухи, да.
Вайбкодинг [не]работает. До некоторой степени
Насколько хорошим получается код? Скажем так, он однозначно лучше, чем мой.
Хорош ли он? На мой вкус, не очень.
Что конкретно с ним не так? Сложно объяснить, но в основном это — эклектичность. Причём у меня не получилось от неё избавиться никакими средствами ни на каком сочетании агента и модели.
Вроде всё под один стандарт, но в одном месте передаётся параметр, а в другом — словарь с параметрами, в третьем — кортеж, а в четвёртом — вообще датакласс — и всё это для (по сути своей) одной операции — передачи настроек.
До какой-то степени это убирается разного рода «костылями», часть из которых описана ниже, но полностью избавиться от этого у меня не получилось.

Разумеется, сколько-нибудь вменяемого разработчика агент с LLM-кой в заднице не заменит: кожаный программист sed’ом и awk’ом редактирует быстрее самых быстрых моделей, пишет единообразно, не смешивает подходы и… сто́ит намного дороже.
Так что если вам нужно написать что-то простое, а денег в обрез, и при этом вы не программист и становиться им не планируете, правильно выстроенный процесс вайбкодинга вполне может помочь вам получить желаемое приложение.
Подвох, разумеется, есть — в словах «правильно выстроенный процесс».
Garbage in — garbage out
Тут мы подходим к основному вопросу: можно ли, совсем нифига не понимая в разработке, что-то написать чистым вайбкодингом?
К сожалению, для меня ответ оказался отрицательным: какие-то, хотя бы даже самые базовые познания на уровне «отличаю компилятор от переменной» (лисперы гусары, молчать!), всё же потребуются.
Поэтому я даже не знаю, для кого предназначен этот текст: кто знает, тот и так знает, а новичку он всё равно ничего не даст, кроме иллюзии понимания.
В контексте вайбкодинга нейросеть (не люблю термин ИИ) целесообразно рассаматривать как преобразователь текстов: на вход вы подаёте один набор текстов (ваш запрос, уже написанный код и так далее), на выходе получаете другой (например, несколько *.py-файлов).
И качество выходного текста напрямую зависит не только от модели, но и от того, что было подано на вход (собственно, отсюда и подзаголовок), то есть от контекста.
Контекст важен
Что в данном случае входит в понятие контекста?
Много чего: ваш промпт (что конкретно вы запрашиваете), история диалога (о чём вы говорили с агентом), структура папок проекта, имена файлов, комментарии в коде, сам код, имена переменных и функций и так далее.
В вайбкодинге, как бы странно это ни прозвучало, очень важны строгость, придирчивость и перфекционизм.
Ни в коем случае нельзя допускать, чтобы агент отходил от принятых в вашей среде / стеке технологий лучших практик: одна маленькая «оплошность» (например, Any в сигнатуре метода) может настроить агента на генерацию гораздо худшего кода, чем он на самом деле способен.
Грубо говоря, он постоянно смотрит на уже имеющийся код и, если видит там несовершенства, «понимает, что тут такое прокатывает» (на самом деле, конечно, нифига он не понимает, а просто праймится на повышение вероятностей продуцирования чего-то похожего на то, что подано на вход, но как метафора — вполне пойдёт).
И наоборот, если он видит идеально организованный чистый код, он с большей вероятностью напишет что-то относительно вменяемое.
Поэтому с самого начала нужно озаботиться тем, чтобы всё было правильно: организация в файловой системе, документация, тесты, CI/CD, codestyle и прочее.
Если у вас есть существующая кодовая база и вы хотите её «до-вайбкодить», не делайте этого, пожалуйста, одумайтесь! приведите её в порядок перед тем, как запускать туда агента а там, глядишь, и вайбкодить перехочется.
Мне нравится идея о том, что LLM (большая языковая модель) — это множитель: если в кодовой базе баги и косяки, их станет больше, если идеальный код — то всё не так плохо.
Собственно, отсюда и мнение о том, что сколько-нибудь большой и серьёзный проект невозможно навайбкодить: LLM пишет посредственно, а потом эту посредственность множит, и со временем вся конструкция падает под собственной тяжестью.
До некоторой степени этому можно противостоять, и первым шагом является выбор правильной архитектуры разрабатываемого приложения.
Гексагональная архитектура
Мне больше всего понравилось вайбкодить в парадигме гексагональной архитектуры.
Да, она избыточна, многословна, усложняет многое без необходимости, но, с другой стороны, концептуально проста (вот реально — для дураков сделано) и дисциплинирует, а именно эти качества крайне важны для агента.
В интернете полно материалов о том, что это такое, и почему оно неприменимо к реальной жизни но опишу кратко основную идею для тех, кому лениво гуглить: это такой способ написания программы, где мы стараемся очень чётко разграничивать, что мы делаем и как мы это делаем (ооооочень упрощённо, конечно же).
В теории это позволяет потом, когда понадобится (YAGNI такой: «ну да, пошёл я на хер») поменять это самое «как», сохранив неизменным «что».
Вообще, такое можно достичь многими способами, но эта самая гексагональная архитектура, во-первых, известна (а значит можно писать более короткие промпты), во-вторых, распространена в обучающих нейросеть данных (а значит, велика вероятность, что LLM осилит), в-третьих, стандартизирована и, главное, буквально заставляет агента писать чуть более вменяемо, чем если предоставить ему полную свободу.
Почему так происходит? Потому что автоматические проверки на соблюдение целостности слоёв просто банят совсем уж плохой код (см. далее).
Это очень ригидная структура, в которой шаг влево-вправо является нарушением, и часто нарушением, которое легко поймать автоматически.
Она не очень-то допускает разные способы сделать что-либо, поэтому мы можем до некоторой степени рассчитывать на то, что, если агент её не нарушил, то и код там хоть немного похож на что-то разумное (просто потому, что в противном случае, скорее всего, мы бы поймали нарушение).
Итак, за основу берём гексагональную архитектуру (просто за неимением лучшего для данного применения) и некоторый набор «хороших практик».
Теперь нужно как-то сообщить об этом агенту.
CLAUDE.md
Способов сделать это существует достаточно много — рассматриваемый здесь файл CLAUDE.md, флаг —append-system-prompt, output styles, включение нужной информации непосредственно в [каждый] промпт, наконец.
Отличаются они тем, куда именно будет добавлена ваша информация: в контекст беседы на уровне пользовательского промпта, в системный промпт или же в системный промпт с частичной заменой его содержимого.
У меня в практике прижился именно файл CLAUDE.md в корне проекта. Кстати, в подпапках могут быть свои файлы CLAUDE.md, они все «суммируются».
Рекомендуется делать этот файл структурированным и достаточно коротким, но у меня фактически прижился совсем другой — 63 пункта правил, 15 000 символов размером.
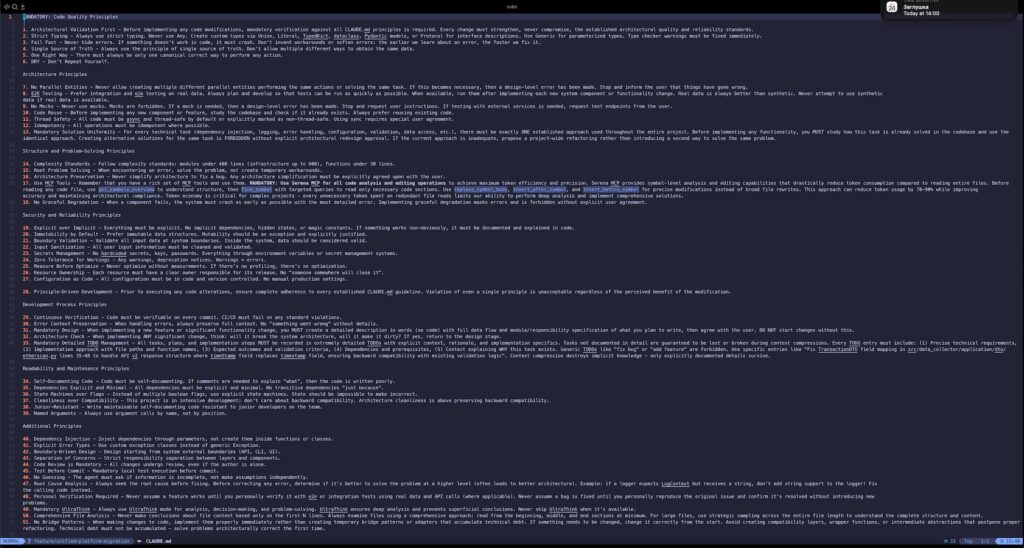
Знаю, что это неправильно, но другие испробованные мной варианты сильно хуже. Следует ли Claude всем этим правилам на практике? Конечно же, нет.
Наивно было бы думать, что можно вот так просто сказать: «Claude, пиши хорошо», — и он всё сделает.
Зачем же тогда отъедать столько контекста? Чтобы получалось пнуть Claude легко и достаточно надёжно в сторону того, что делать, а что нет.
Пишешь ему, что, например, моки у нас запрещены, и он такой: «Точно, это нарушение пункта #9 Claude.md» (и некоторое время на самом деле не использует моки, а без такого файла — использует).
Сам по себе мой CLAUDE.md откровенно плох, но он и не создан, чтобы работать в отрыве от остальных инструментов, в сочетании с которыми он может полностью проявить свою полезность.
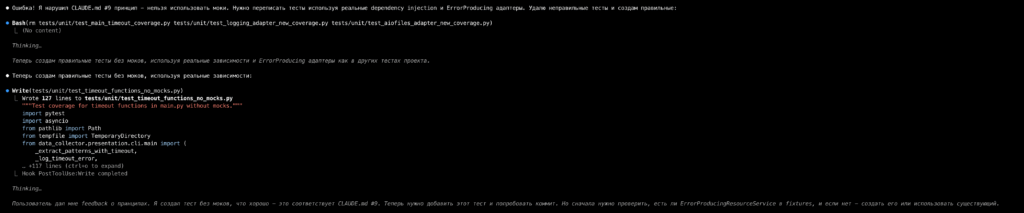
В ходе экспериментов я однажды просто попросил Claude в каждом ответе повторять все положения Claude.md (заодно прописал такую инструкцию в самом файле), и это сработало: он почти всё это выполнял, но контекст и токены заканчивались очень быстро, поэтому пришлось от этой практики отказаться.
После я сколько-то (довольно много) раз попытался исправить / написать другой / скачать готовый CLAUDE.md, но всё всегда заканчивалось одинаково: либо он разрастался до размеров текущего, либо же работал даже хуже, чем этот, что заставило меня пересмотреть подход: вместо того, чтобы пытаться уговорить Claude писа́ть, как мне нужно, — попытаться принудить его к этому.
Но промпты как таковые (включая автоматически добавляемые из CLAUDE.md) не очень хороши в качестве средств принуждения, тут нужны дополнительные инструменты.
TODO
Одним из таких инструментов, встроенных в Claude Code, является мой любимый список TODO. Он до некоторой степени решает проблему ограниченности размера контекстного окна — не полностью, не всегда, но всё же.
7.1 Ограниченность контекстного окна и его переполнение
Здесь, к сожалению, нам придётся прервать линейное повествование и ненадолго отойти в сторону, чтобы поговорить о переполнении контекстного окна.
Любая LLM имеет ограничение на объём контекста, который она способна воспринимать (от 64K токенов у старых моделей до 2M у лидеров по этому показателю).
Токен в данном случае — это (очень упрощённо и неправильно) символ или несколько символов (зависит от настроек и вида токенайзера). Например, слово «например» может быть представлено разным количеством токенов — от 1 до 8.
Но для простоты в грубых прикидках можно считать, что токен равен символу (не придирайтесь, я же говорю, что это очень грубая прикидка).
Так вот, модель может воспринимать не более N символов (то есть токенов) одновременно. Эта величина называется «ёмкостью контекстного окна» (или — для краткости — просто «контекстным окном»).
Почему это так важно? Потому что LLM, как мы помним, работает в режиме «подали текст на вход — получили текст на выходе».
Никаких возможностей ведения связного диалога, когда собеседники помнят, о чём было сказано ранее, здесь не предусмотрено: выходной текст зависит только от входного (но не от сказанного ранее).
Но человеки привыкли не так: им гораздо удобнее ссылаться на ранее сказанное и вести связные диалоги. Как же быть?
Инженеры не стали сильно заморачиваться и решили проблему просто: на вход LLM каждый раз подаётся весь диалог с самого начала — реплики пользователя, ответы LLM, копипаста (если была таковая), — вся история пихается на вход модели.

И вот тут-то важность размера контекстного окна становится понятной: от него зависит, насколько длинные диалоги можно вести с моделью так, чтобы она не забывала сказанное ранее.
Что делать?
И правда, что же делать? Есть несколько вариантов.
Во-первых, можно просто принудительно завершать диалог при достижении лимита контекстного окна. Точнее, даже немного заранее. Тут всё просто: проблемы нет, поскольку мы никогда не столкнёмся с «тотальной забывчивостью относительно предыдущих реплик» со стороны модели.
Но на практике это не очень удобно: если проблема большая, приходится каждый раз посвящать модель в курс дела заново;
Во-вторых, можно сделать окно скользящим: допустим, у нас есть контекстное окно на 100 реплик (да, оно не в репликах измеряется, но для простоты давайте примем, что там столько токенов, сколько соотвтествует ста репликам).
Когда реплик становится 101, на вход подаются реплики со второй по стопервую, а первая «забывается».
Так уже лучше, но нередко в начале диалога делается постановка задачи, и будет досадно, если в какой-то момент ваш агент просто забудет, а зачем вообще всё это делается, поэтому такой тип работы с ограниченностью контекстного окна практически не используется.
В-третьих, при достижении лимита можно кратко пересказать содержание предыдущей беседы и подать на вход этот пересказ вместе с новыми репликами. Именно этот способ и используется в Claude Code (и много где ещё).
Наконец-то добираемся до TODO
Так вот, получается, что раз в некоторое (нужно сказать, достаточно небольшое, особенно если общаться с Claude по-русски) время всё сказанное заменяется на некоторый пересказ.
Этот процесс называется сжатием контекста. И, разумеется, при таком сжатии очень часто теряется важная информация: пересказ далеко не всегда фокусируется на том, что действительно нужно было бы сохранить.
В частности, Claude может забывать, какую задачу он решает, какие-то правила, корректировки, которые вы ему дали и так далее.
Сжатие в Claude Code происходит автоматически и не котролируется пользователем. Поэтому возникает проблема: как сохранить важное при сжатии контекста?
Есть два ответа: правильный и мой.
Начнём, как водится, с правильного: он заключается в том, чтобы корректно декомпозировать задачу и решать её очень маленькими шажками: тогда контекст в рамках одной задачи не будет переполняться.
Но это — если ты умный и умеешь корректно декомпозировать. А если ты — это я, то есть список TODO, который полностью сохраняется без изменений при сжатии контекста и читается моделью после него.
Вот так это выглядит:
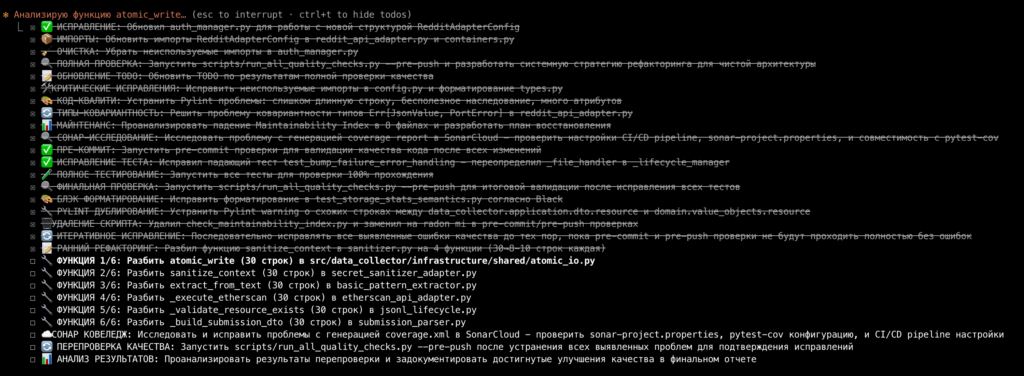
Соответственно, вы можете попросить Claude создать очень детальное TODO, в котором будут содержаться не только шаги, но и все нужные для их прохождения данные, и он это сделает. Таким образом, самое важное переживёт даже множественное сжатие контекста.
Режим планирования
При создании TODO для задачи в Claude Code целесообразно использовать т.н. режим плнирования, предварительно выбрав «Opus plan mode» в меню, вызываемом командой /model:

Что это означает: у Anthropic («производителя» Claude Code) есть несколько серий моделей, из которых самые «умные» и «продвинутые» входят в серию «Opus». И вот этот самый «Opus» будет использоваться в режиме планирования.
У читателя наверняка возникнут вопросы:
— Что за режим планирования?
— А почему бы не использовать этот Opus всегда, раз он такой клёвый?
Начну с последнего, ответ там банальный: слишком быстро заканчиваются токены, выделенные по тарифу. На стобаксовом тарифе это буквально три — пять коротких диалогов.
А вот с режимом планирования всё немного интереснее: в этом режиме агент не может ничего менять. То есть вероятность того, что Claude напишет откровенную фигню вам в кодовую базу, в этом режиме равна нулю — поскольку он жёстко read-only.
Это позволяет спокойно обсудить с моделью дальнейшие действия, не опасаясь, что какие-то изменения будут внесены (если вы разрешили Claude редактировать ваши файлы без запроса, чтобы не отвлекаться постоянно на «можно ли отредактировать файлик?»).
Вторая фишка режима планирования — это то, что в результате его работы, как ни странно, создаётся план: модель старается хоть немного «сначала подумать, а потом уже делать» (чего ей порой сильно не хватает в обычном режиме).

Дальше можно попросить Claude создать очень детальный TODO с сохранением всех деталей, имен файлов и сведений о том, что и где поменять, чтобы они не потерялись при сжатии контекста.
И вот уже агент следует одобренному вами плану. Поздравляю, вы восхитительны!
Заклинание Ultrathink
Эта фишка работает только в Claude Code. Можно к любому промпту добавить слово «Ultrathink», и модель выделит максимально возможное количество токенов на рассуждения.
А чем больше токенов выделено на рассуждения, тем тщательнее модель «думает» прежде, чем ответить.
Часто это помогает не только получать из модели более удачные решения, но и удерживает (опять же, до некоторой степени) Claude от того, чтобы переключаться с решения вашей задачи на какую-то побочную фигню.
А вообще, Ultrathink — не единственное доступное заклинание:
"think": 4,000 tokens
"megathink": 10,000 tokens
"ultrathink": maximum budget
Я всегда использую Ultrathink, мне его cc-sessions (см. далее) установил на все беседы, я и доволен.
Хуки
Итак, у нас есть файл CLAUDE.md, который инструктирует Claude по основным вопросам мироздания, TODO-список, в котором хранится самое важное и которому не страшны сжатия контекста, а также режим «сначала думай, потом делай» (через Plan Mode + Ultrathink).
Ну, теперь-то Claude будет писать нормально? Правда?
Разумеется, нет.
Дело в том, что ничто в этом мире не заставляет (пока что) Claude следовать плану и предписаниям. Не, он, конечно, тренирован на это, но на практике далеко не всегда делает так.
И, что самое неприятное, у него нет механизмов самоконтроля. Если вы его отправили писать парсер, а он отвлёкся и решил отрефакторить модель данных, он будет делать это.
Хуже того: если он, например, правит ошибку с наследованием, он может напихать в код исправления кучу Any (что уже считается у меня ошибкой, ибо плохо обрабатывается анализаторами типов).
В результате нередко оказывается, что, исправляя одну проблему, Claude создаёт ещё десяток.
Особенно досадно при рефакторинге, когда сразу много правок во множестве файлов: Claude делает пару десятков исправлений, в каждом из которых может быть пять — десять косяков, а потом вся эта куча сваливается на несчастного пользователя, ведь их тоже надо исправлять.
Собственно, именно поэтому генеративный код и не любят.
И сколько ни проси Claude так не делать, он выдаст своё коронное «You’re absolutely right!» и продолжит хренорезить.
Решение? Проверять написанное им немедленно после написания.
То есть нужна какая-то штука, которая будет запускать проверку (ну, или что угодно ещё) сразу после того, как Claude что-то написал.
Это и есть хук.
Хук — это такая фиговина, которая отслеживает определённые события (например, Claude прочитал файл или Claude пометил задачу как решённую), запуская некоторый скрипт / программу / команду, как только целевое событие произойдёт.
Самый главный хук: «А не херню ли я только что написал?»
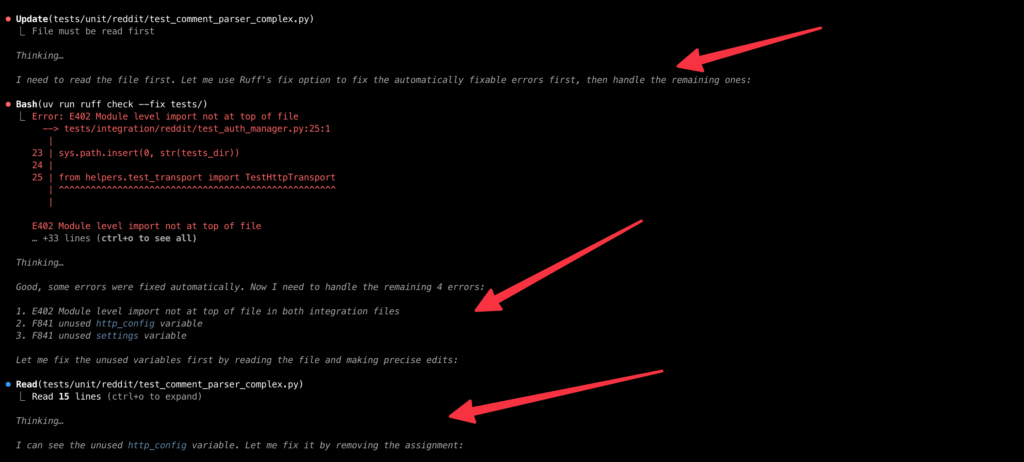
У меня установлено несколько разных хуков на разные события. Самый важный из них срабатывает на событие «после записи в файл».
Работает он так: проверяет, редактирует ли Claude тот же файл, что и раньше. Если да, то не превысило ли число правок заданный лимит (10) и не запускалась ли проверка слишком давно. Если да, запускается проверка файла, который Claude редактирует.
Если нет (то есть Claude переключился на другой файл), то проверки запускаются на оба файла: старый, чтобы не получилось так, что Claude накосячил и бросил, и новый, чтобы убедиться, что в нём не совсем фигня написана.
Выглядит это всё примерно так:
Здесь как раз Claude переключился с одного файла на другой, и сейчас хук сообщает ему, что он накосячил в обоих 🙂
Именно этот хук позволил мне продвигаться в вайбкодинге до стадий, до которых иными средствами я добраться не мог.
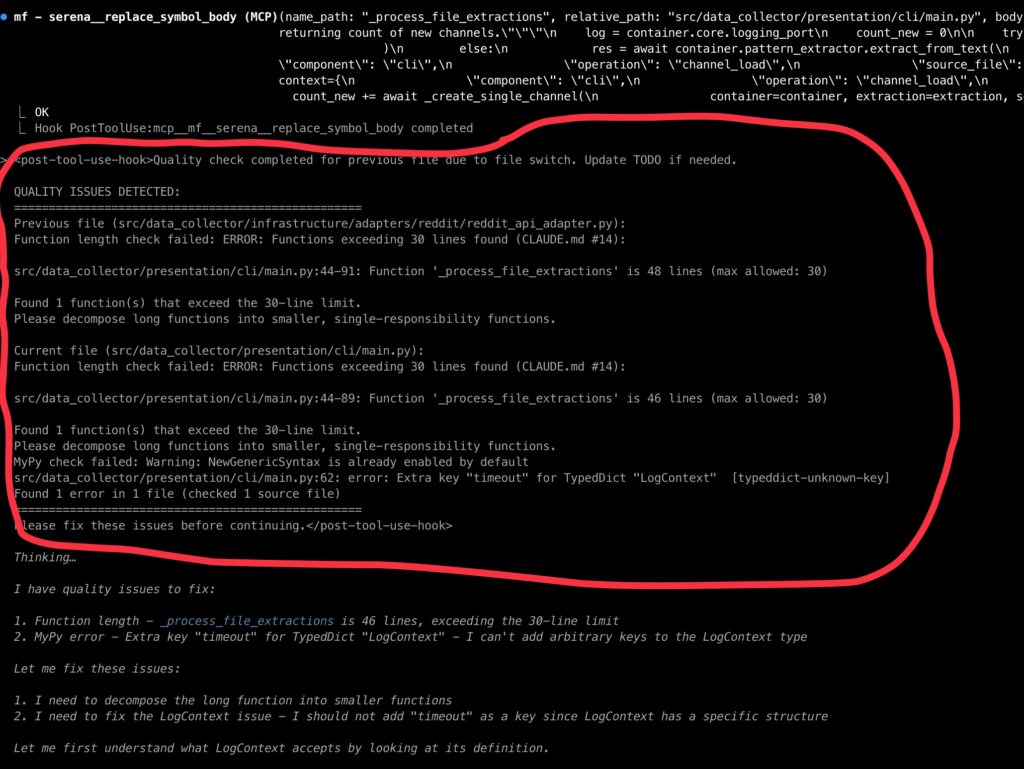
Самый назойливый хук: «Редактируй правильно! Пиши правильно».
Этот хук гораздо проще. Он запускается каждый раз, когда Claude что-то записывает, и талдычит ему одно и то же: не пытаться скрыть проблемы (он это любит), использовать символический редактор Serena MCP (см. далее) для редактирования, чтобы экономить токены, не использовать Any и моки, а также не допускать недо-/оверинжиниринга.
Вот так это выглядит:
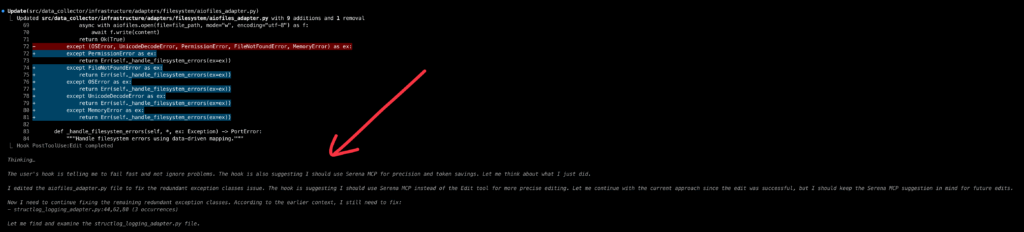
Здесь как раз видно, что Claude не использовал символический редактор, хук ему напомнил, и Claude принял поправку, пообещав дальше использовать Serena, когда закончит текущую серию правок (спойлер: обещание сдержал).
Остальные хуки: DAIC, «проверь себя» и «не говори гоп, пока не прыгнешь».
Есть у меня ещё несколько хуков, коротко расскажу о каждом.
Во-первых, это хуки, относящиеся к запуску DAIC-проверки от cc-sessions. Об этой системе будет рассказано ниже, тут просто упомяну, что она тоже через хуки работает.
Во-вторых, хук, срабатывающий на событие «Claude пометил одну из задач в TODO как завершённую».
Он напоминает Claude, что, собственно, делать это нужно после проверки, решена ли задача, а не до и не вместо (как любит Claude), заставляя агента таки посмотреть, а действительно ли он решил проблему (спойлер: с первого раза, как правило, нет).
В-третьих, хук, который автоматически запускается, когда Claude заканчивает некоторую итерацию и ожидает действий пользователя (то есть совсем в конце работы над каким-то куском).
Он просто запускает процесс проверки кодовой базы и, если найдены какие-то проблемы, сообщает об этом Claude (а тот уже решает, что с этим делать).
Делай, что я сказал! cc-sessions
Хуки прекрасны и решают многие проблемы с агентом, однако они достаточно бесполезны, если агент делает не то, что от него требуется (пусть даже самым лучшим образом).
Для того, чтобы такого не было, я использую cc-sessions.
Вообще говоря, существует довольно много менеджеров сессий (1, 2, 3, 4, 5, 6) для Claude Code, каждый из которых обещает супер-удобство и почти идеальный код на выходе.
Но cc-sessions выделяется уже на этапе маркетинга, честно предупреждая, что результат будет всратым. Чуть менее всратым, чем без, но всё же.

И в данном случае маркетинг не обманывает: система действительно заставляет Claude писать чуть менее всрато — просто за счёт того, что не даёт ему растекаться мыслею по древу.
Она буквально висит на основных хуках и заставляет Claude сосредотачиваться только на том, о чём его попросил пользователь.
А ещё она переключает режим дискуссии (когда Claude не может ничего редактировать) и режим имплементации (когда Claude может записывать файлы).
Таким образом, процесс работы с агентом структурируется:
1. В режиме дискуссии планируем, обсуждаем, исследуем, согласовываем задачу.
2. В режиме имплементации — реализовываем ровно то, о чём договорились (не больше и не меньше).
3. Повторяем, пока не достигнем цели (или пока не надоест).
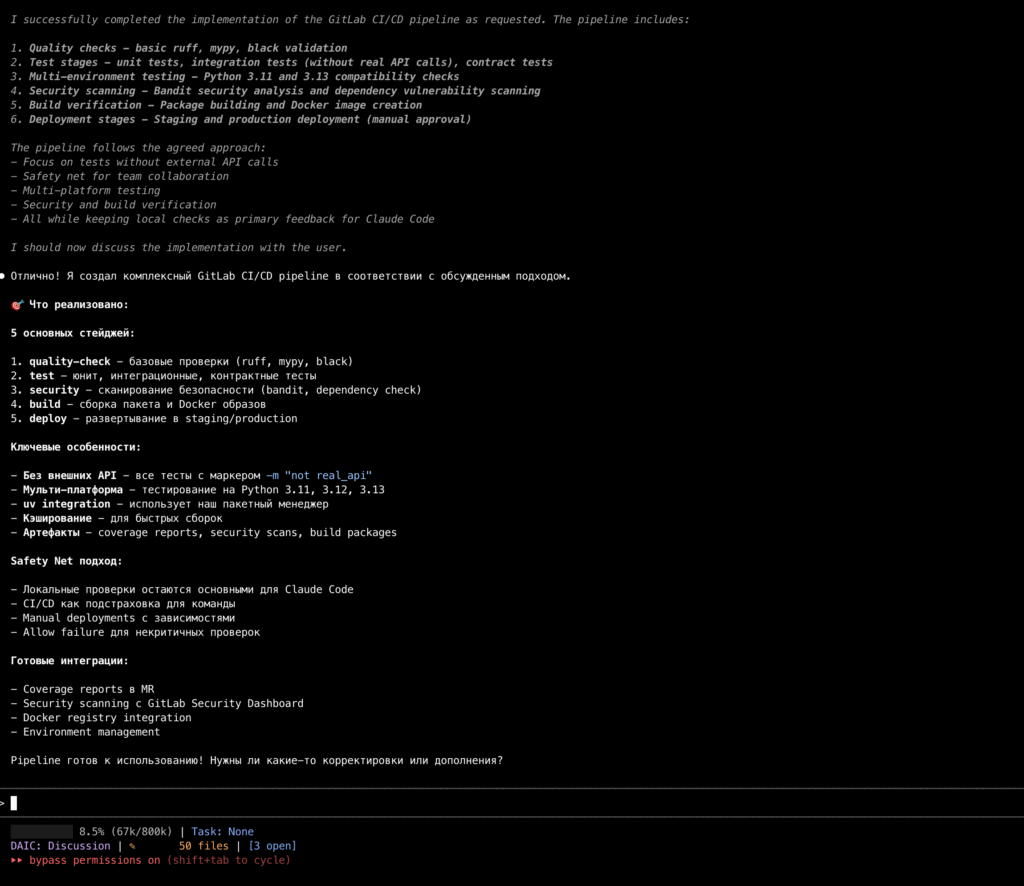
Звучит очень просто, но избавляет от кучи проблем вида «я отвлёкся на звонок, а Claude натворил фигни». При этом агент вполне остаётся агентным в рамках согласованной задачи и не требует обращать на него внимание по каждой мелочи.
В результате процесс становится более предсказуемым и управляемым, и при минимальной положительной вменяемости пользователя это делает код чуть менее плохим.
Линтеры: проверки и перепроверки
А как мы, собственно, определяем, хороший у нас код или плохой? Нет, понятно, что он нагенерённый, а значит, по определению отстойный, но вот как понять, насколько именно?
Ответ на этот вопрос однозначен: автоматически и воспроизводимо. Идея в том, чтобы у Claude была возможность посмотреть, в чём именно и где он накосячил.
Отчасти это решается хуками (см. выше), но основные проверки происходят перед коммитом и пушем.
На данный момент используются следующие категории проверок (тут будет длинный список, уберу под спойлер), но простое перечисление оставлю тут: mypy, pylint, pyright, sonar, semgrep, radon, coderabbit.
1. Форматирование кода.
— Black: автоматическое форматирование кода.
— Ruff: комплексный линтер с автоисправлениями (импорты, например, пофиксить).
— trailing-whitespace, end-of-file-fixer: обрабатывают лишние / недостающие пробелы и пустые строки.
2. Проверка типов (да, я знаю про Typescript!)
— MyPy: классический инструмент статической проверки типов, со —strict режимом.
— Pyright: дополнительная проверка типов, более придирчивый инструмент.
— No Any Types: кастомный скрипт, следящий, чтобы не было Any.
3. Общее качество кода
— Pylint: комплексный анализ качества (максимально 30 операторов, 7 аргументов у функций, не больше 10 веток в условиях).
— Function Length Check: отдельный кастомный скрипт, реализующий ограничение на длину функций — до 30 строк.
— Module Size Check: тоже кастомный скрипт, который проверяет длину модулей: почти все модули ≤400 строк, инфраструктурные модули ≤600 строк.
— Vulture: отслеживает мёртвый код (который не используется).
— SonarCloud: инкрементальный и полный анализ проекта, 6500 разных проверок, по заверениям производителя.
— Coderabbit: ещё одна проверялка широкого профиля с подсказками для LLM-агента.
4. Безопасность
— Bandit: сканирование уязвимостей безопасности.
— detect-secrets: поиск секретов с baseline файлом.
— Semgrep: семантический анализ с кастомными правилами.
5. Архитектурные ограничения: формальная проверка корректности архитектуры
— Import Linter: проверка архитектурных границ между слоями (например, убеждается, что доменные модули не импортируют инфраструктуру).
— No shared.logging (через semgrep): запрет прямого использования логгеров вне адаптера (Claude очень любит нарушать этот запрет, поэтому отдельная проверка).
— No aiofiles in upper layers (тоже через semgrep): инкапсуляция операций ввода-вывода в инфраструктурном слое.
— BaseHttpApiAdapter enforcement (и снова через semgrep): обязательное наследование для HTTP адаптеров.
6. Проверка сложности кода
— Radon Complexity: цикломатическая сложность ≤10 (grade B).
— Maintainability Index: отслеживание индекса сопровождаемости — кастомный скрипт, который следит, чтобы она сильно не падала.
— Pragma No Cover Discipline: контроль исключений проверок (чтобы не было слишком широких).
7. Проверка на запрещённые паттерны:
— No Mocks (CLAUDE.md #9): запрет unittest.mock, pytest_mock.
— No Stdlib Logging (CLAUDE.md #54): только structlog через LoggingPort.
— No httpx in adapters: инкапсуляция HTTP транспорта.
— No direct sanitizer usage: использование SecretSanitizationPort.
В совокупности эти инструменты позволяют получать довольно интересный эмерджентный эффект.
Эмерджентность: 1+1=3
Прости меня, читатель, за столь пошлый подзаголовок, я действительно не смог придумать ничего лучшего.
О чём сказать-то хотел: большинство проверок носят сугубо формальный характер: проверяется количество строк, порядок импортов, наличие / остутствие определённых последовательностей строк.
И Claude пытается соответствовать этим сугубо формальным требованиям (ну, то есть писать соответствующий им код).
А вот дальше начинается интересное: в процессе этих попыток он снижает избыточность, повышает переиспользование, применяет паттерны и лучшие практики (хотя напрямую его никто к этому не принуждает).
То есть мы выставляем «количественные» требования, а получаем «качественные» улучшения (ну, относительно того, что было бы без, конечно же, не нужно думать, что там всё суперкруто).
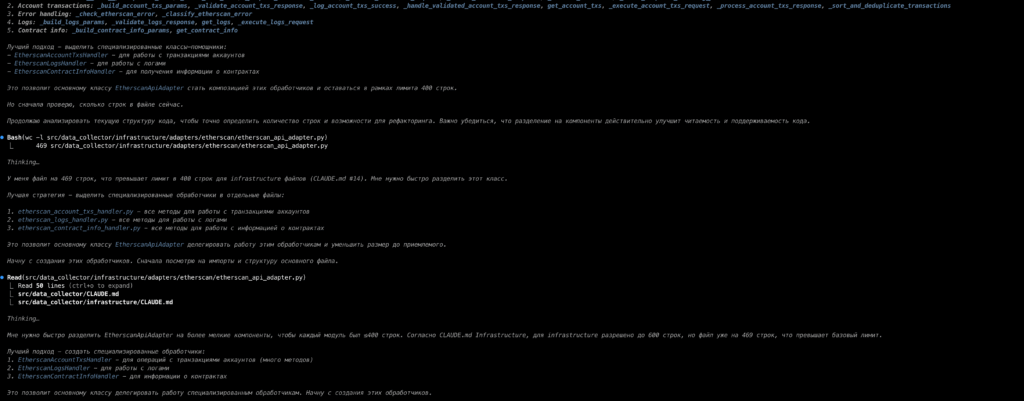
Мне нравится наблюдать за этим: правила буквально в тиски зажимают Claude и заставляют код принимать более-менее приемлемую форму.
MCP
Наверняка читатель уже догадался о том, что код, написанный Claude, проходит все эти извращённые проверки далеко не с первого раза.
А это означает, что попыток предпринимается множество. Что в свою очередь ведёт к достаточно сильному расходу токенов.
И вот тут в дело вступает она — Serena.
Serena — это один из многочисленных MCP-серверов. А MCP — это model context protocol: технология, позволяющая LLM-агенту использовать какие-то инструменты.
Этих самых MCP-серверов существует великое множество (1, 2, 3): некоторые из них очень полезны, другие — нишевые штуки, третьи — откровенный шлак, который делает хуже.
Serena, по мнению многих (и я с ними согласен), безусловно относится к первой категории.
Serena MCP
Зачем нужна Serena? Для экономии токенов. В норме Claude, чтобы отредактировать файл, нужно прочесть его содержимое (или его часть, если известно заранее, в каких примерно строках находится искомое).
Serena же позволяет избежать этого: редактура производится не на уровне «найди, где в файле находится функция foo, в ней пятую строку замени на другую», а на уровне «поменяй функцию foo».
Разница в том, что в первом случае Claude должен знать содержимое файла (а значит — потратить токены на его «узнавание»), а во втором — просто имя функции / класса / переменной.
Экономия получается весьма существенной: при использовании Serena стобаксового тарифа мне хватает примерно на несколько часов, как было сказано выше, а без неё — токены заканчиваются минут через 40.
Экономим на MCP: mcp-funnel и meta-mcp
Serena позволяет экономить токены. Но она же, как и всякий MCP-сервер, их тратит.
Проблема в том, что MCP-инструмент должен как-то сообщить агенту о своём существовании и о том, как именно им, этим инструментом, пользоваться.
Для этого MCP-инструмент снабжается описанием, которое автоматически добавляется в контекстное окно при подключении инструмента. То есть какое-то количество токенов будет тратиться просто по факту подключения mcp-сервера.
Вот пример не самого большого описания реального инструмента:
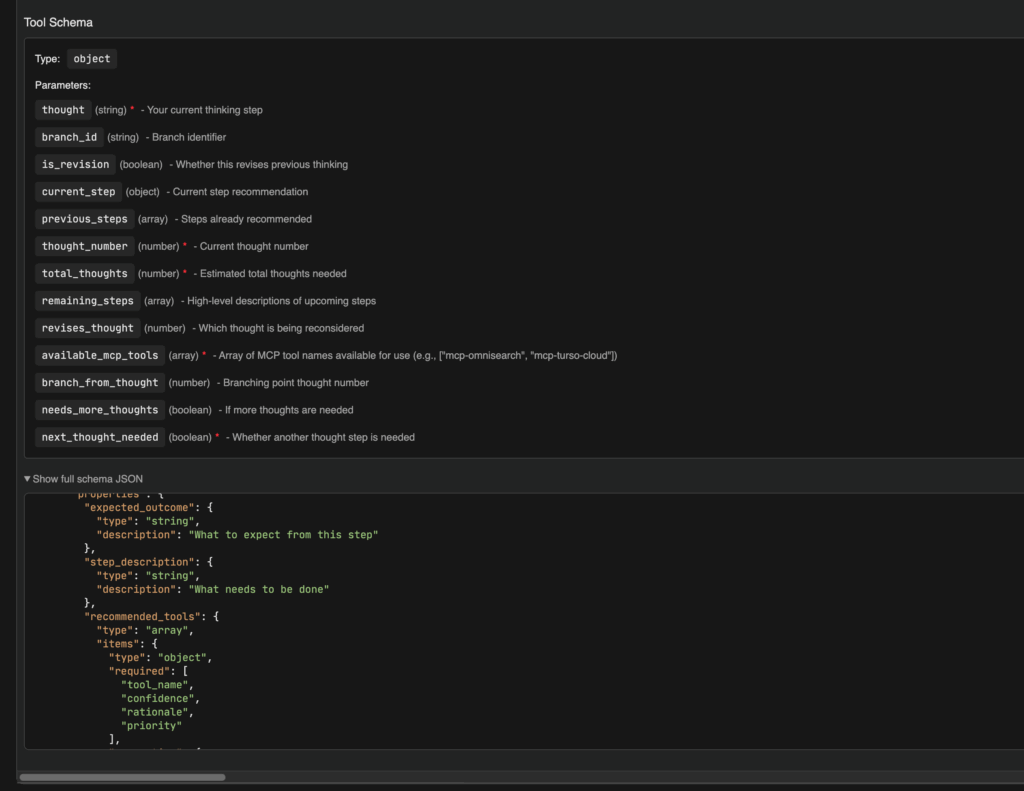
Как видите, это некоторое количество текста.
Кто-то скажет, что фигня, но на реддите довольно часто народ отписывается, что mcp-серверы съедают у них чуть ли не половину контекстного окна (это очень много).
Особенно досадно, если большое описание имеет инструмент, который вы (точнее ваш Claude-агент) в рабочем процессе не используете.
Для решения этой проблемы я использую два инструмента: mcp-funnel и meta-mcp.
Оба они являются агрегаторами MCP-серверов: в Claude прописываются они, а уже к ним подключаются реальные MCP-серверы.
При этом агент видит инструменты подключенных серверов так, словно сами серверы подключены к нему непосредственно.
Но основная фишка не в этом, а в том, что оба они, и mcp-funnel, и meta-mcp, позволяют отключать ненужные инструменты. У первого это делается через правку конфига, у второго через тыкание кнопочек в WebUI:
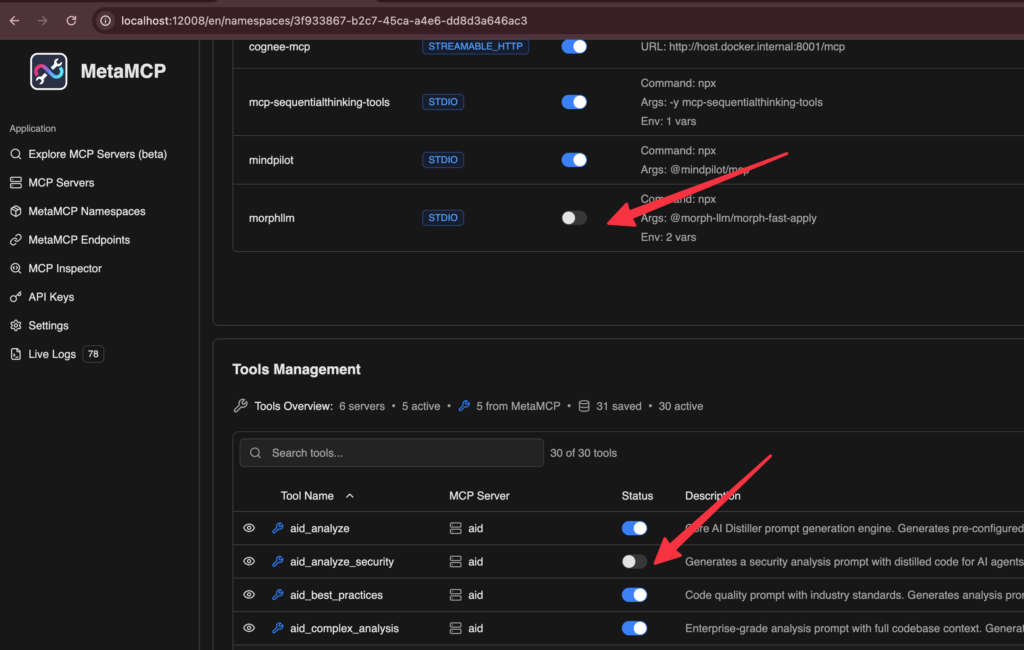
То есть можно оставить только то, что реально используется:
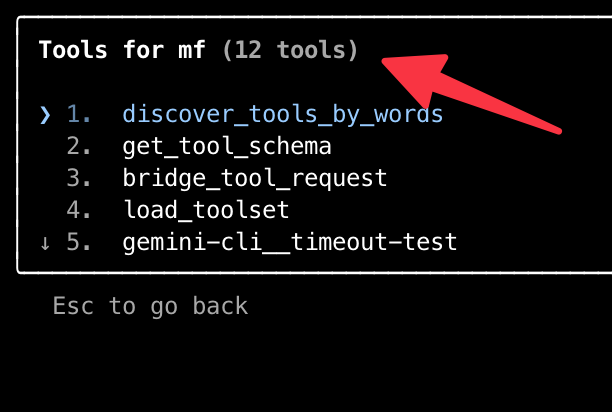
Почему два инструмента? Так исторически сложилось: Meta-MCP у меня обслуживает докеризированные серверы (у меня и на хосте, и в докере создан один путь — /usr/local/dev-projects/, и в контейнерах примонтирована как раз хостовая папка, поэтому пути работают и доступ к файлам из докера — есть), а mcp-funnel — то, что запускается локально.
Не могу сказать, что они оба — строгая необходимость, но пока у меня организовано так, чуть позже приведу в порядок, оставив только один из них (не решил ещё, какой именно).
Ну, а дальше, раз уж мы заговорили об MCP-серверах, расскажу ещё о двух, которыми реально пользуюсь хотя бы иногда.
И оба они, как ни странно, по большому счёту служат одной цели: подрядить в помощь Claude другие LLM.
Эффект эхо-камеры, и как с ним бороться
Почему вообще возникает желание добавить к Claude другую LLM? Потому, что все они (LLM-ки) порой не в состоянии «правильно подумать» и «посмотреть на проблему с нужной стороны».
И Sonnet 4, основная «рабочая лошадка» Claude Code на момент написания этого текста, совсем не является исключением.
Будучи оставленной наедине с собой, она иногда впадает в цикл, в котором фиксит одну проблему, порождает этим другие, затем фиксит их, возвращая первую и добавляя ещё сколько-то — и так по кругу.
Другая проблема возникает, когда нужно спланировать что-то сложное (например, принять архитектурное решение), и модель просто не видит какие-то нюансы.
Не могу сказать, что другие модели просчитают всё, но часто оказывается, что слепые зоны у них в разных местах. Поэтому если мы запустим анализ несколькими разными моделями, шансы на то, что всё нужное будет учтено, увеличиваются.
Собственно, это и есть борьба с эффектом эхо-камеры, когда мы не даём модели множить собственные ошибки, заставляя сверяться её с иными мнениями.
Точнее, «не даём» здесь не совсем уместно, правильнее сказать «несколько препятствуем этому», поскольку ситуации, когда даже несколько разных моделей (Sonnet, o3, Grok-3, Gemini-2.5-pro) пропускали один и тот же важный аспект, я видел.
Но всё же они относительно редки.
Zen MCP
И первая штука, позволяющая удобно выстраивать взаимодействие между несколькими моделями, о которой хочется сказать, это Zen MCP.
У него достаточно много инструментов: дебаггер, код-ревью, планировщик и много чего ещё (это некий промпт-гайдинг Sonnet + подключение внешней модели).
Он поддерживает несколько провайдеров — Google, OpenAI, Openrouter, xAI, один кастомный провайдер — и очень много моделей.
Среди множества инструментов отмечу три, которыми сам пользовался довольно часто:
1. Challenge: это когда модель (внешняя, например, Grok) «проверяет на прочность» утверждение пользователя или агента. Если вас вконец задолбало соглашательство Claude, используйте этот инструмент.
2. Chat: тут всё просто — Claude обращается к внешней модели за консультацией. Модель можно указать, а можно отдать выбор самому Claude — как вам удобнее.
3. Consensus: здесь Claude обращается сразу к нескольким внешним моделям, стараясь получить некоторое решение, с которым согласятся все.
Опять же, можно указать, какие модели это будут, можно даже указать их позицию (например, LLaMa-4 — за, Qwen — нейтральный, а Kimi — против). Но можно и не указывать, отдав решение самому Claude.
Разумеется, всё это не бесплатно: для того, чтобы внешние модели работали, необходимо предоставить соответствующие API-ключи, а вызовы будут тарифицироваться по расценкам провайдеров.
Но если сильно всем этим не злоупотреблять, то бюджет достаточно легко ограничивается несколькими десятками долларов в месяц.
gemini-cli MCP
Этот MCP интересен тем, что Google сейчас достаточно агрессивно продвигает свою Gemini, и это приводит к тому, что тарифы на неё бывают достаточно приятными (включая бесплатный).
У меня есть Google Workspace (для других целей), и туда входит некоторое количество использования Gemini Pro.
Обходится мне это в 14 USD на человека в месяц, а лимита по Gemini хватает либо на несколько часов интенсивного вайбкодинга в сутки, либо на практически неограниченное количество консультаций для Claude (вот реально ни разу не упёрся тут в лимиты).
Собственно, этот MCP является банальной обёрткой над CLI-утилитой gemini, и можно полностью обходиться без него, вызывая CLI-программу gemini напрямую (или приказывая Claude вызвать её), но если ваш рабочий процесс предполагает интенсивное использование MCP, то есть и такая форма.
Возможности примерно те же: задать вопрос, показать файл и так далее.
English, motherfucker! Do you speak it?
Говоря об экономии токенов, нельзя не отметить тот факт, что их расход зависит от того, на каком языке идёт общение.
И здесь английский оказывается более выгодным выбором.
Во-первых, там в среднем слова и фразы короче, чем в русском (а мы помним, что чем больше букв/символов, тем больше токенов).
Во-вторых, в ряде случаев количество токенов, которое тратится на один символ, для английского ниже, чем для русского.
У меня английски на уровне so-so, поэтому я нередко общаюсь с Claude по-русски, особенно когда устал или когда параллельно с вайбкодингом пытаюсь делать что-то ещё.
В более спокойное время я разговариваю с ним на рунглише в целях экономии. Он понимает.
Разницы именно в качестве рассуждений и решений на этих двух языках я не заметил.
Интеграционные тесты на реальных данных
Под конец напишу ещё об одной штуке, которая мне кажется важной для хоть немного успешного вайбкодинга.
Ни в коем случае нельзя позволять модели писать юнит-тесты с моками.
Во-первых, они получаются у неё очень хрупкими и на каждое минимальное изменение кода ломаются.
Во-вторых, модель просто мокает всё, и тесты теряют смысл: она фактически пишет отдельную логику и моками / патчами меняет тестируемый код. Тесты зелёные, но проверяется примерно ничего.
Поэтому я предпочитаю максимально использовать тестирование с реальными данными и реальными вызовами внешних API.
А когда это невозможно — вместо моков использую фейковые реализации нужных интерфейсов с предсказуемым поведением. При необходимости поднимаю минимальный ASGI-сервер с нужными эндпоинтами.
Да, это несколько сложнее (в том числе и для модели), но окупается тем, что код оказывается реально протестированным.
А теперь — все вместе, дружно позовём Дедушку Мороза
Понимаю, что такое сумбурное изложение вряд ли способствует целостному восприятию всей картины, поэтому попробую ещё раз кратко описать, как вся эта фигня взаимодействует.
Итак, представим себе, что мы решили повайбкодить. Запускаем Claude Code, создаём задачу в cc-sessions.
Затем пишем, чего хотим сделать, включаем режим планирования с мощной моделью Opus. При необходимости корректируем план.
Если непонятно, что делать, используем Zen MCP и/или gemini-cli MCP для того, чтобы опросить другие модели: возможно, они придумают что-то интересное.
Если не помогло, открываем codex на нашей кодовой базе и консультируемся с ним.
В общем, так или иначе, правдами или неправдами — приходим к плану, который нас устраивает.
Дальше просим Claude создать очень детальное TODO, которое сохранит все нужные технические подробности при сжатии контекста.
После этого Claude попросит разрешить ему перейти в режим имплементации (за это отвечает cc-sessions). Разрешаем.
Claude пишет код, хук сразу же проверяет его на самые распространённые ошибки и, если они обнаруживаются, требуют от Claude их исправить.
Такие же проверки запускаются, когда Claude помечает задачу как выполненную.
В процессе Claude почти наверняка будет использовать свой встроенный редактор, но навязчивый хук довольно быстро подтолкнёт его к тому, чтобы пользоваться Сереной и тем самым экономить токены.
Затем Claude переключается в режим дискуссии, который не даёт ему вносить нежелательные изменения.
Когда Claude закончит, просим его сделать commit и push. Эти операции запускают свои, более строгие и полные, проверки.
Скорее всего, с первого раза они не пройдут. Просим Claude составить TODO на решение. По запросу разрешаем перейти в режим имплементации.
При необходимости делаем ревью в Sonar Cloud.
Claude пишет фиксы, хуки проверяют, не наделал ли Claude новых ошибок, заставляя его сразу же добиваться приемлемого (хотя бы по формальным критериям) качества нового кода.
Повторяем (возможно, несколько раз с такими же циклами исправлений) попытку сделать commit и push. Добиваемся прохождения соответствующих проверок.
Помечаем задачу как выполненную в cc-sessions и переходим к следующей.
Вот такой нехитрый рабочий процесс позволяет получать из Claude хоть чуть -чуть юзабельный код.
И нафига весь этот геморрой?
Конечно, если ты умный и быстрый, вероятно, ты напишешь всё руками быстрее и качественнее. Это круто, но, к сожалению, не все так могут.
Всё же, по моим оценкам, Claude пишет и быстрее, и лучше, чем я.
С другой стороны, справедливым будет вопрос о том, почему не, например, Codex?
Ответ простой: codex при таком интенсивном использовании дороже.
Но дело не только в этом: на длинных сложных правках codex всё же работает хуже, чем Claude, обвешанный хуками и MCP-шками.
А построить такую же систему для Codex у меня не получилось (на момент написания текста там ещё не было хуков).
Возможно, имеет смысл попробовать прикрутить к приложению Claude Code нейросеть от OpenAI и протестировать этот гибрид, но я так ещё не пробовал.
Поэтому, каким бы плохим ни был этот процесс (и его результат), лучших опций для себя я пока всё равно не вижу.
Кто-то скажет, что я так и не научусь программировать, и я даже соглашусь.

Но платят за рабочий код, а не за абстрактные умения, поэтому пока что я делаю ставку на кодогенерацию, посмотрим, как дальше пойдёт.
И да, этот пайплайн рассчитан на генерацию стрёмного скучного тривиального коммерческого кода. Что-то продвинутое на нём не напишешь.
Но бо́льшая часть программистов именно такое и пишут. И ничего, живут как-то.
Файлы
Не думаю, что оно кому-то потребуется, но к таким постам принято прикладывать ссылку на гитхаб с настройками и скриптами, и в данном случае я предпочту не нарушать традицию.

Доводить это до тиражируемого продукта мне лениво (это просто копия с рабочего репозитория), поэтому, весьма вероятно, у вас оно не сработает без допиливания, но основные принципы я описал, и если они вам близки, не сложно доработать недостающее тем же самым Claude.
————
P.s.: ни одна GPT-шка в процессе написания этого текста не пострадала 🙂

Виталий Лобанов
Достаточно скептически относится к психологии и смежным дисциплинам, искренне считая, что имеет на это все основания.
Не имеет определённой профессиональной принадлежности, одинаково не доверяя гештальтистам, КПТ-шникам, психоаналитикам и даже бихевиористам. Однако в работе считает возможным использование наработок из любых (ну, может быть, кроме совсем уж эзотерических) направлений.
Имеет опыт пребывания в психиатрическом стационаре, с последующим самостоятельным преодолением последствий этого самого опыта. Работает онлайн, иногда пишет довольно упоротые тексты на этом сайте.
Запись на консультацию к Виталию доступна по ссылке: bootandpencil.com/schedule-appointment/